6 Modeling big data

Source: http://tinyurl.com/y95rd2jx
6.1 Introduction to machine learning
Machine learning is automating the automation – Dr. Pedro Domingos
Machine Learning (ML) is an important aspect of modern business applications and research nowadays. Through advanced mathematical models, ML algorithms can figure out how to perform important tasks either intuitively or by generalizing from existing observations (i.e., sample data). This is often feasible and cost-effective where manual programming is not. ML algorithms utilize sample data – also known as training data – to make decisions without being specifically programmed to make those decisions. As more data points become available, ML algorithms assist computer systems in progressively improving their performance so that more ambitious and complex problems can be tackled. As a result, ML has begun to be widely used in computer science and other fields, including educational measurement and psychometrics. Some ML applications include web search, spam filters for e-mails, recommender systems (e.g., Netflix and YouTube), credit scoring, fraud detection, stock trading, and drug design.
Some examples of ML in educational testing and psychometrics include automated essay scoring applications, personalized learning systems, intelligent tutoring systems, and learning analytics applications to inform instructors, students, and other stakeholders.
6.1.1 Focus of machine learning
As an inductive approach, ML focuses on making accurate predictions based on existing data, NOT necessarily hypothesis testing (see Figure 6.1).
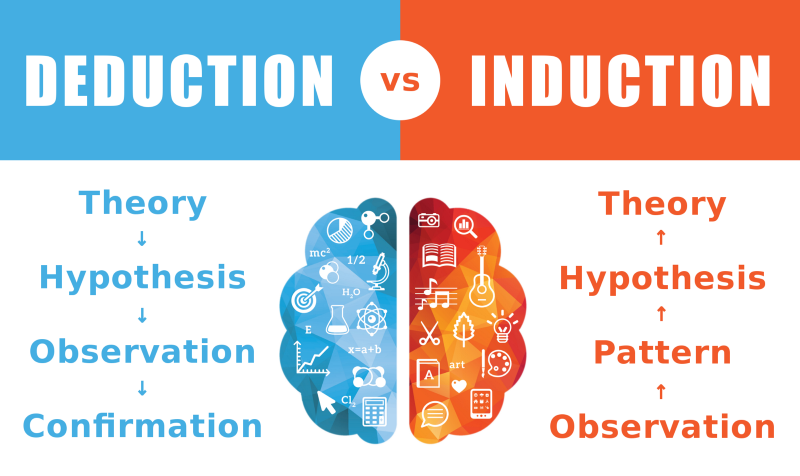
Figure 6.1: Deduction vs. induction (Source: https://tinyurl.com/yxtt8afm)
Also, ML aims to learn from the data to tell you how to utilize the variables for a prediction scenario, NOT to give you output for a program that you wrote (see Figure 6.2).
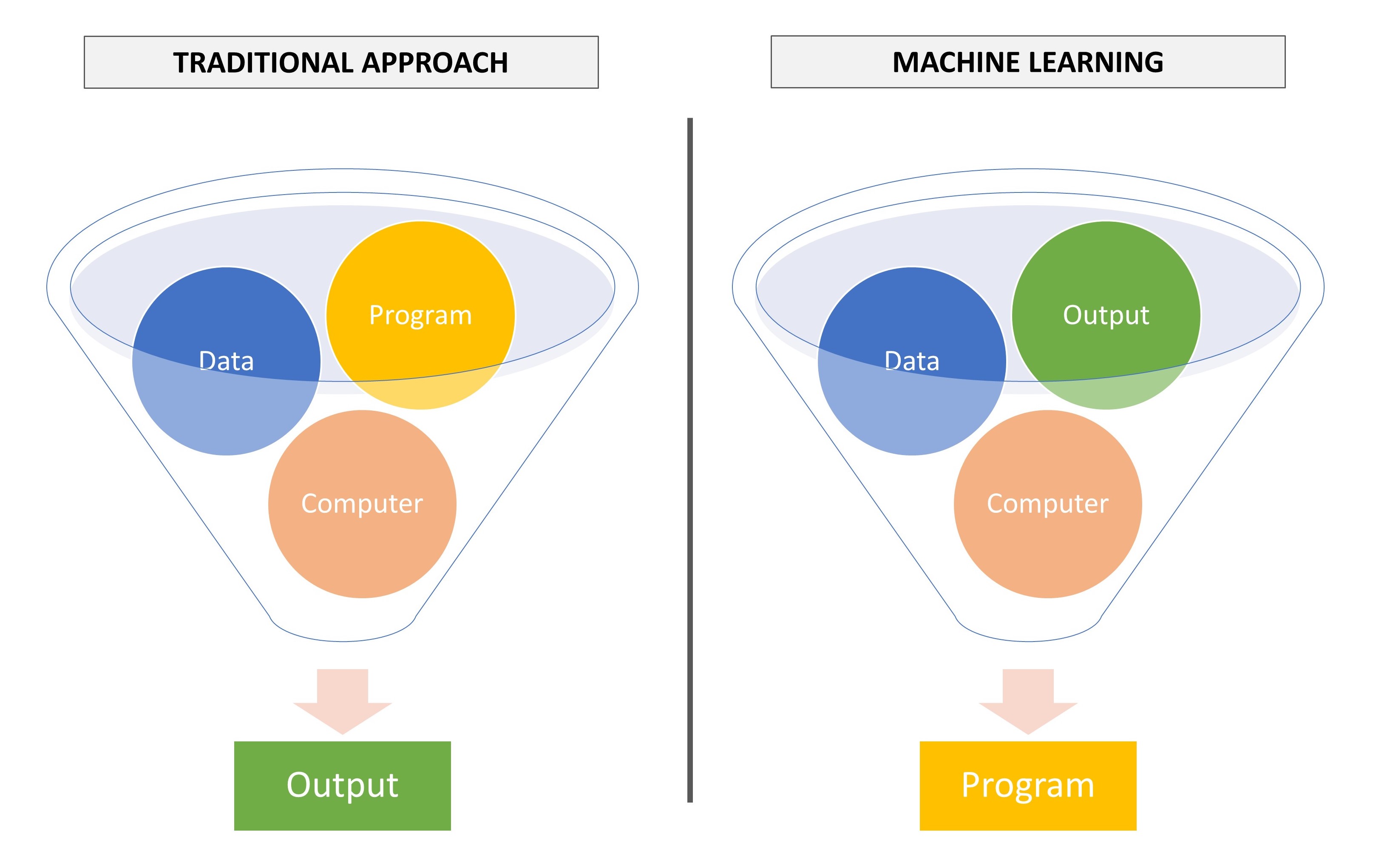
Figure 6.2: Traditional programming vs. machine learning
6.1.2 Some concepts underlying machine learning
Here we want to introduce some important ML concepts, based on Dr. Pedro Domingos of University of Washington titled “A Few Useful Things to Know about Machine Learning”. According to Dr. Domingos, all machine learning algorithms generally consist of combinations of three elements:
(Statistical) Learning from data = Representation + Evaluation + Optimization
Representation: A classifier is a system that inputs (typically) a vector of discrete and/or continuous feature values (i.e., predictors) and outputs a single discrete or continuous value (i.e., dependent or outcome variable). To build a ML application, a classifier must be represented in some formal language that the computer can handle. Then we should consider questions such as “how do we present the input data?” “how do we select what features/variables to use?” and so on. We will review some of these classifiers today – such as decision trees, support vector machines, and logistic regression.
Evaluation: An evaluation function is necessary for distinguishing good classifiers from bad ones. The evaluation function used internally by the algorithm may differ from the external one that we want the classifier to optimize. Common evaluation methods include accuracy/error rate, mean squared or absolute error (for continuous outcomes) and precision, accuracy, recall (i.e., sensitivity), and specificity (for categorical outcomes).
Optimization: An optimization method is necessary for searching among the classifiers in the language for the highest-scoring (i.e., most precise) one. The choice of optimization technique is key to the efficiency of the learner. Some optimization methods include greedy search, gradient descent, and linear programming.
6.1.3 Model development
There are several elements that impact the success of model development in ML:
- Amount of data: Although there are many sophisticated ML algorithms available to researchers and practitioners, they all rely on the same thing – data. Selecting clever ML algorithms that are capable of making the most of the available data and computing resources is important. However, without enough data, even the most sophisticated ML algorithms will return poor-quality results. Nowadays enormous amounts of data are available, but there is not enough time to process all of it.
You can have data without information, but you cannot have information without data. – Daniel Keys Moran
- Data quality: Data quality is the essence of ML applications. ML is not magic; it can’t get something out of nothing. The better quality data we provide, the more reliable and precise results we can obtain.
More data beats clever algorithms, but better data beats more data. – Peter Norvig
- Data wrangling: Big data are often not in a form that is amenable to learning, but we can construct new features from the data – which is typically where most of the effort in a ML project goes. Data wrangling is the most essential skill for building a successful ML model. The processes of gathering data, integrating it, cleaning it, and pre-processing it are very time-consuming. Furthermore, ML is not a one-time process of building data and running a model to learn from the data, but rather an iterative process of running the model, analyzing the results, modifying the data, tweaking the model, and repeating.
Data scientists spend 60% of their time on cleaning and organizing data. – Gil Press
- Feature engineering: Feature engineering is the key to building a successful ML model. Feature engineering refers to selecting and/or creating the most useful variables in a big dataset for a given purpose (e.g., classification). If there are many independent features that correlate well with the outcome variable, then the learning process is easy. If, however, the outcome variable is a very complex function of the features, then learning doesn’t occur very easily. Categorical features nearly always need some treatment where we can use one hot encoding (similar to dummy coding) to convert such features into a form that could be provided to ML algorithms to do a better job in prediction.
Applied machine learning is basically feature engineering. – Andrew Ng
6.1.4 Model evaluation
ML models that focus on classification problems are often evaluated based on classification accuracy, sensitivity, specificity, and precision (see Figure 6.3).
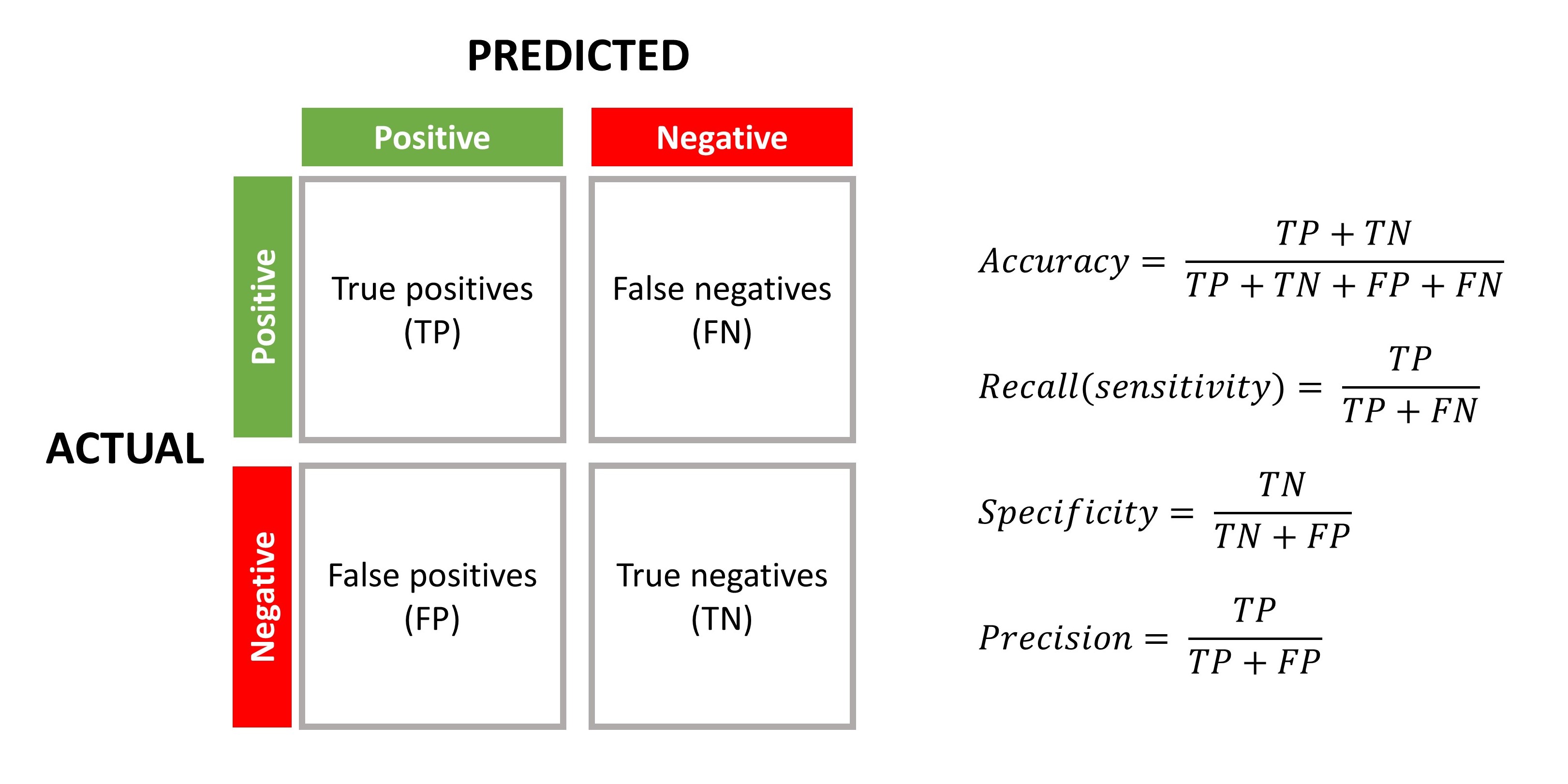
Figure 6.3: Confusion matrix for classification problems
ML models that focus on regression problems are evaluated based on the fitted regression line and actual data points, as shown in Figure 6.4. Using the difference between observed data points (blue) and predicted data points (red), we can creata a summary index of error – such as mean absolute error, mean squared error, and root mean squared error.
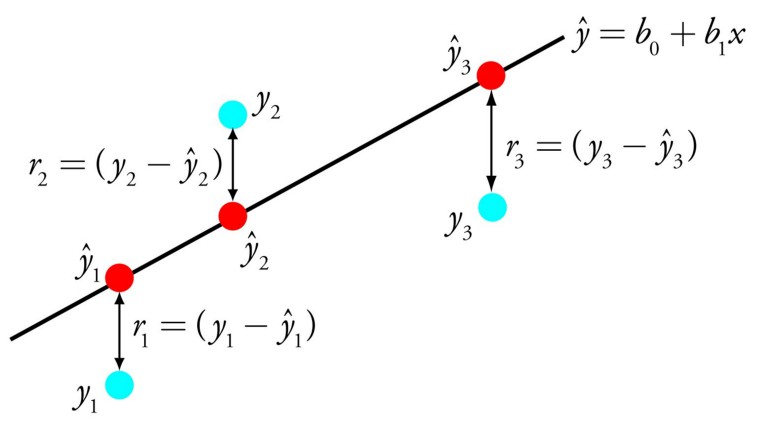
Figure 6.4: A demonstration of simple linear regression
- Mean Absolute Error (MAE):
\[ MAE = \frac{1}{N} \sum_{j=1}^N |y_i-\hat{y}_i| \]
where \(N\) is the number of observations, \(y_i\) is the observed value of the outcome variable for observation \(i\), and \(\hat{y}_i\) is the predicted value for the outcome variable for observation \(i\).
- Mean Squared Error (MSE):
\[ MSE = \frac{1}{N} \sum_{j=1}^N (y_i-\hat{y}_i)^2 \]
- Root Mean Squared Error (MSE):
\[ RMSE = \sqrt{MSE} \]
Figure 6.5 shows a typical machine learning pipeline that illustrates the flow of the model development and evaluation elements.
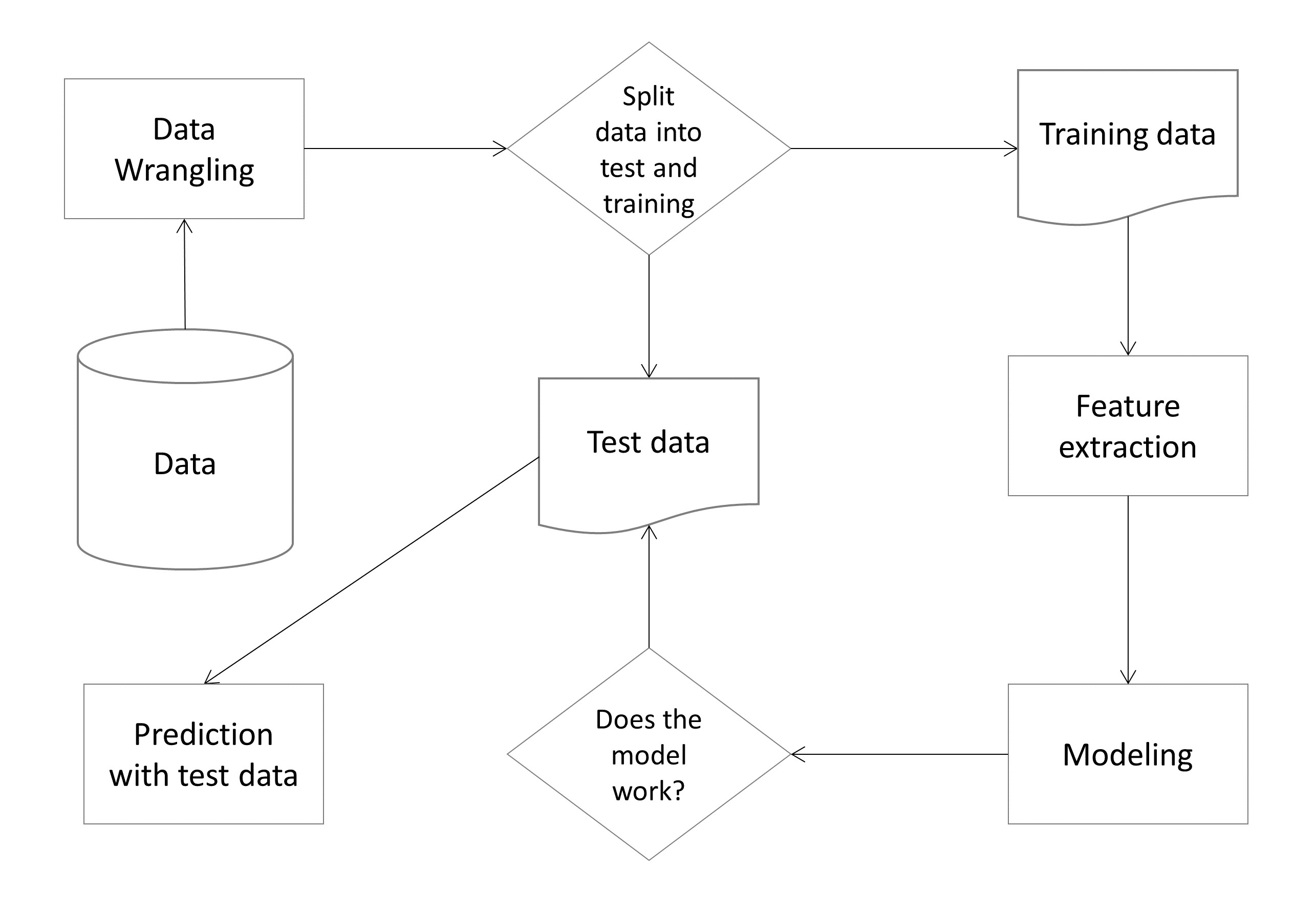
Figure 6.5: A typical machine learning pipeline
6.1.5 Key issues
In ML applications, generalization refers to how well the concepts learned by a machine learning model apply to specific examples (i.e., new data that the model hasn’t seen yet). Therefore, the fundamental goal of ML is to build a model that can generalize beyond the examples seen in training data. Regardless of how many observations we have in training, the model will produce inaccurate results for at least some observations in the test data. This is primarily because we are very unlikely to see those exact examples from training data again when testing the model with new (or validation) data. That is, getting highly precise results in training data is easy, whereas generalizing the model beyond training data is hard. Therefore, most machine learning beginners would easily fall for the illusion of success with training data and then get immediately disappointed with the results from new data.
When we talk about how well a ML model learns from training data and generalizes to new data, there are two key issues: overfitting and underfitting.
Overfitting refers to a model that models the training data too well. It happens when a ML model learns the detail and noise in the training data to the extent that it negatively impacts the performance of the model on new data. In the context of automated essay scoring, overfitting would occur when all the essays (including words, punctuation, word combinations) from the training data are used to maximize the accuracy of the essay scores. Because the model would be very specific to the words or phrases used by students in the training data, the same ML model would yield very poor results when the essay is given to a different group of students who write essays quite differently (e.g., English language learners). Overfitting typically occurs with ML models that implement nonparametric and nonlinear function to learn from the data (e.g., neural network models).
Underfitting refers to a ML model that can neither model the training data nor generalize to new data – which means that our ML attempt was a complete failure. An underfit machine learning model is not a suitable model and will be obvious as it will have poor performance on the training data. The obvious remedy to underfitting is to try alternate ML algorithms. Nevertheless, it does provide a good contrast to the problem of overfitting.
Both overfitting and underfitting may cause poor performance of ML algorithms; but by far the most common problem in ML applications is overfitting. There are two important techniques that we can use when evaluating ML algorithms to limit overfitting:
- Use a resampling technique to estimate model accuracy: The most popular resampling technique is k-fold cross validation. This method allows us to train and test our model k-times on different subsets of training data and build up an estimate of the performance of a ML model on unseen data. Using cross validation is a gold standard in ML applications for estimating model accuracy on unseen data (see Figure 6.6).

Figure 6.6: An illustration of k-fold cross validation
- Hold back a validation dataset: If we already have new data (or very large data from which we can spare enough data), using a validation dataset is also an excellent practice.
In conclusion, we ideally want to select a model at the sweet spot between underfitting and overfitting. As we use more data for training the model, we can review the performance of the ML algorithm over time. We can plot both the outcome on the training data and the outcome on the test data we have held back from the training process.
Over time, as the ML algorithm learns, the prediction error for the model on the training data goes down and so does the error on the test data. If we train the model for too long, the performance on the training data may continue to decrease because the model is overfitting and learning irrelevant details and noise in the training dataset. At the same time, the error for the test set starts to increase again as the model’s ability to generalize decreases. The sweet spot is the point just before the error on the test data starts to increase where the model has good accuracy on both the training data and the unseen test data.
6.2 Types of machine learning
In general, ML applications can be categorized in two ways:
- Supervised learning vs. unsupervised learning
- ML for classification problems vs. ML for regression problems
In supervised learning, ML algorithms are given training data categorized as input variables and output variables from which to learn patterns and make inferences on previously unseen data (testing data). The goal of supervised learning is for machines to replicate a mapping function we have identified for them (for example, which students passed or failed the test at the end of the semester). Provided enough examples, ML algorithms can learn to recognize and respond to patterns in data without explicit instructions. Supervised machine learning is typically used for classification tasks, in which we segment the data inputs into categories (e.g., for pass/fail decisions, strongly agree/agree/neutral/disagree/strongly disagree), and regression tasks, in which the output variable is a real value, such as a test score. The accuracy of supervised learning algorithms typically is easy to evaluate, because there is a known, “ground truth”" (output variable) to which the algorithm is optimizing (see Figure 6.7).
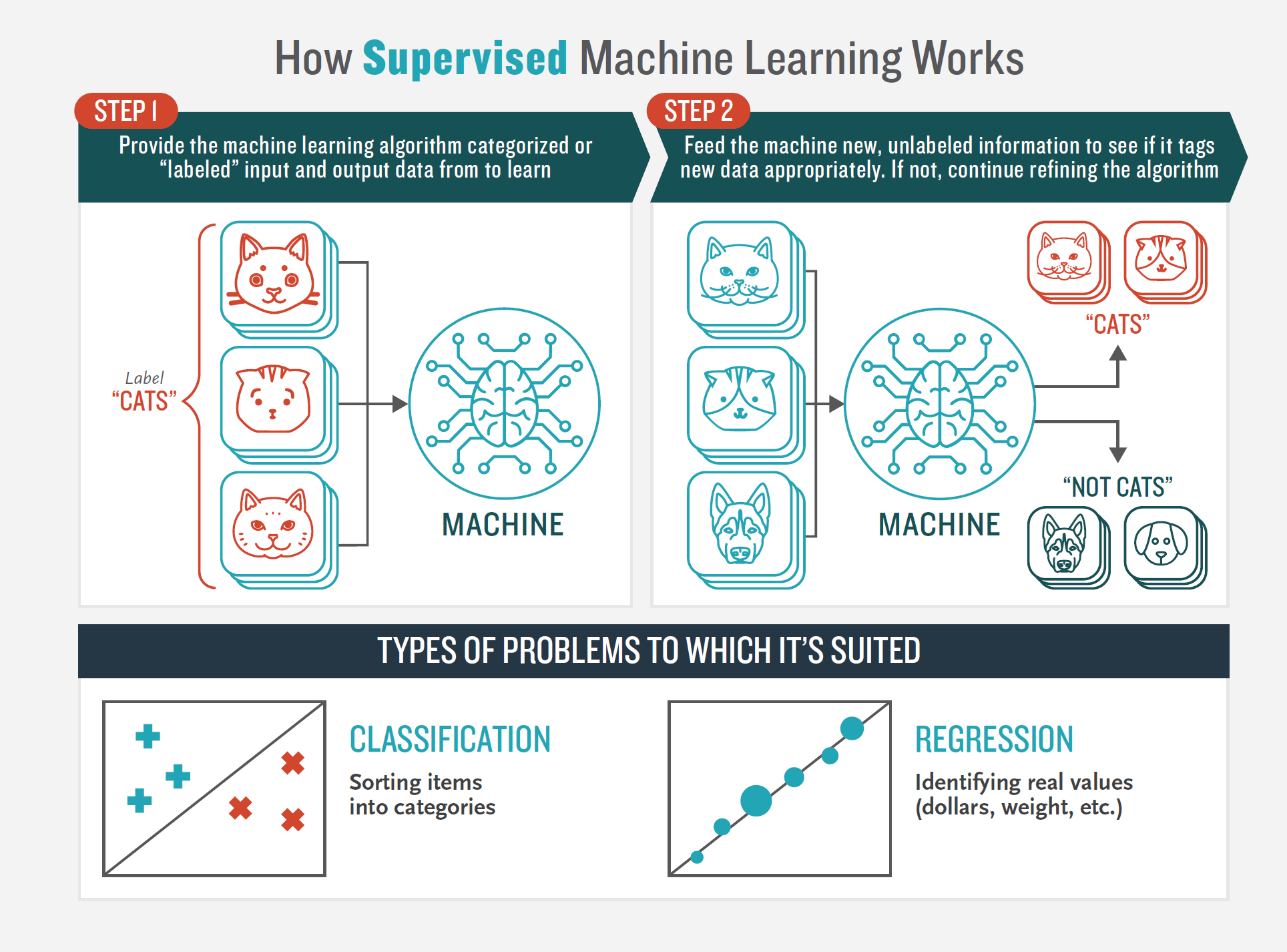
Figure 6.7: How supervised machine learning works
Unsupervised machine learning is an approach to training ML in which the algorithm is given only input data, from which it identifies patterns on its own. The goal of unsupervised learning is for algorithms to identify underlying patterns or structures in data to better understand it. Unsupervised learning is closer to how humans learn most things in life: through observation, experience, and analogy. Unsupervised learning is best used for clustering problems – for example, grouping examinees based on their response times and engagement with the items during testing in order to detect anomalies. It is also useful for “association,” in which ML algorithms independently discover rules in data; for example, students who tend to answer math items slowly also tend to answer science items slowly. The accuracy of unsupervised learning is harder to evaluate, as there is no predefined ground truth the algorithm is working toward (see Figure 6.8).
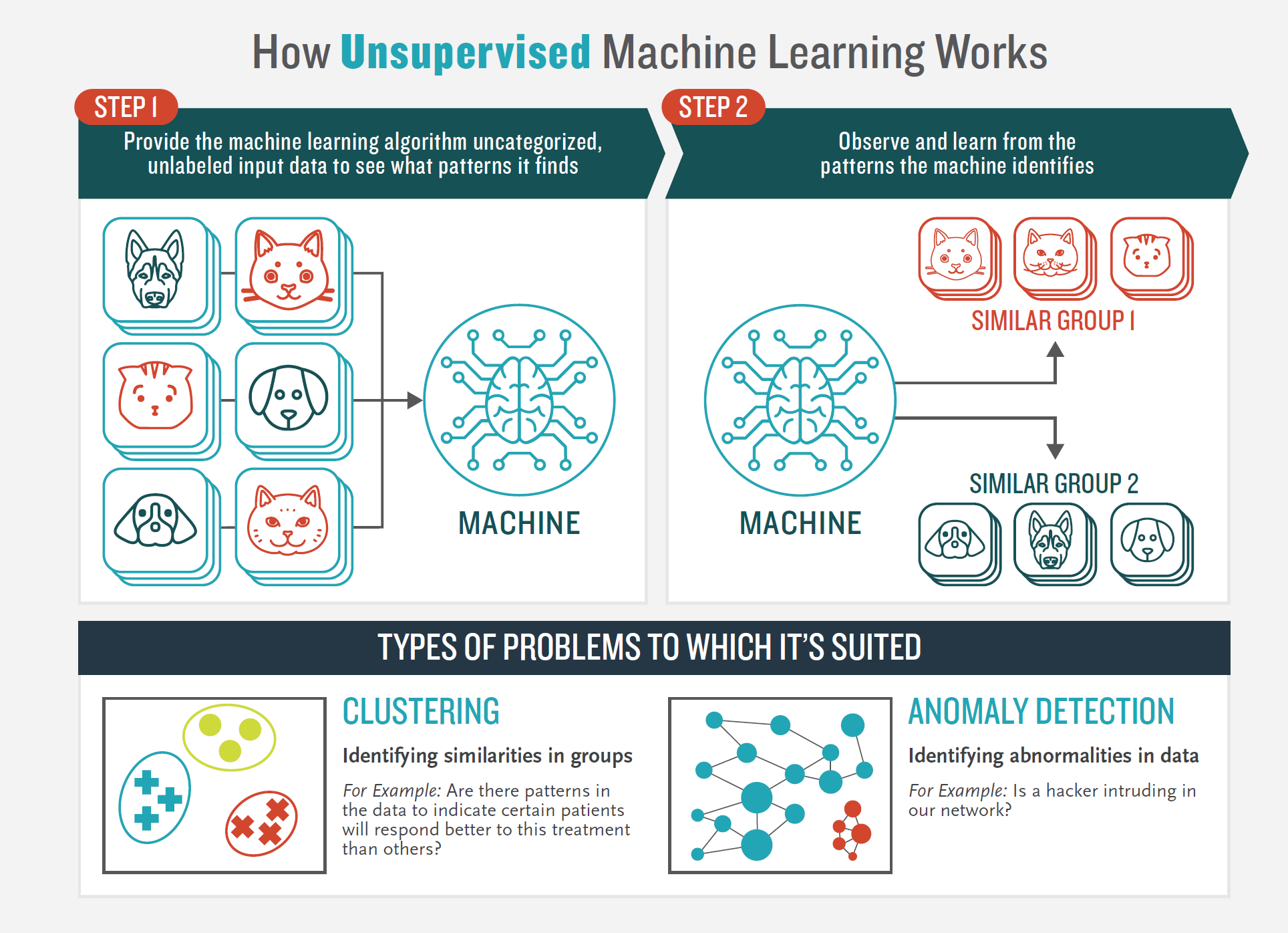
Figure 6.8: How unsupervised machine learning works
Figure 6.9 below shows most widely used algorithms for both supervised and unsupervised ML applications. The last column in Figure 6.9 refers to “reinforcement learning” – a more specific type of machine learning – but we will not be covering reinforcement learning in this training session.
Figure 6.9: Widely used machine learning algorithms